The Llama 3 Herd of Models
Llama Team, AI @ Meta1
1A detailed contributor list can be found in the appendix of this paper.
Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a
new set of foundation models, called Llama 3. It is a herd of language models that natively support
multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with
405B parameters and a context window of up to 128K tokens. This paper presents an extensive
empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language
models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and
post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input
and output safety. The paper also presents the results of experiments in which we integrate image,
video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach
performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The
resulting models are not yet being broadly released as they are still under development.
Date: July 23, 2024
Website: https://llama.meta.com/
1 Introduction
Foundation models are general models of language, vision, speech, and/or other modalities that are designed
to support a large variety of AI tasks. They form the basis of many modern AI systems.
The development of modern foundation models consists of two main stages: (1) a pre-training stage in which
the model is trained at massive scale using straightforward tasks such as next-word prediction or captioning
and (2) a post-training stage in which the model is tuned to follow instructions, align with human preferences,
and improve specific capabilities (for example, coding and reasoning).
In this paper, we present a new set of foundation models for language, called Llama 3. The Llama 3 Herd
of models natively supports multilinguality, coding, reasoning, and tool usage. Our largest model is dense
Transformer with 405B parameters, processing information in a context window of up to 128K tokens. Each
member of the herd is listed in Table 1. All the results presented in this paper are for the Llama 3.1 models,
which we will refer to as Llama 3 throughout for brevity.
We believe there are three key levers in the development of high-quality foundation models: data, scale, and
managing complexity. We seek to optimize for these three levers in our development process:
• Data. Compared to prior versions of Llama (Touvron et al., 2023a,b), we improved both the quantity and
quality of the data we use for pre-training and post-training. These improvements include the development
of more careful pre-processing and curation pipelines for pre-training data and the development of more
rigorous quality assurance and filtering approaches for post-training data. We pre-train Llama 3 on a
corpus of about 15T multilingual tokens, compared to 1.8T tokens for Llama 2.
• Scale. We train a model at far larger scale than previous Llama models: our flagship language model was
pre-trained using 3.8 × 1025 FLOPs, almost 50× more than the largest version of Llama 2. Specifically,
we pre-trained a flagship model with 405B trainable parameters on 15.6T text tokens. As expected per
1
�
Finetuned Multilingual
Long context
Tool use
Release
Llama 3 8B
Llama 3 8B Instruct
Llama 3 70B
Llama 3 70B Instruct
Llama 3.1 8B
Llama 3.1 8B Instruct
Llama 3.1 70B
Llama 3.1 70B Instruct
Llama 3.1 405B
Llama 3.1 405B Instruct
�
�
�
�
�
�
�
�
�
�
�1
�
�1
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
�
April 2024
April 2024
April 2024
April 2024
July 2024
July 2024
July 2024
July 2024
July 2024
July 2024
Table 1 Overview of the Llama 3 Herd of models. All results in this paper are for the Llama 3.1 models.
scaling laws for foundation models, our flagship model outperforms smaller models trained using the
same procedure. While our scaling laws suggest our flagship model is an approximately compute-optimal
size for our training budget, we also train our smaller models for much longer than is compute-optimal.
The resulting models perform better than compute-optimal models at the same inference budget. We
use the flagship model to further improve the quality of those smaller models during post-training.
• Managing complexity. We make design choices that seek to maximize our ability to scale the model
development process. For example, we opt for a standard dense Transformer model architecture (Vaswani
et al., 2017) with minor adaptations, rather than for a mixture-of-experts model (Shazeer et al., 2017)
to maximize training stability. Similarly, we adopt a relatively simple post-training procedure based
on supervised finetuning (SFT), rejection sampling (RS), and direct preference optimization (DPO;
Rafailov et al. (2023)) as opposed to more complex reinforcement learning algorithms (Ouyang et al.,
2022; Schulman et al., 2017) that tend to be less stable and harder to scale.
The result of our work is Llama 3: a herd of three multilingual1 language models with 8B, 70B, and 405B
parameters. We evaluate the performance of Llama 3 on a plethora of benchmark datasets that span a wide
range of language understanding tasks. In addition, we perform extensive human evaluations that compare
Llama 3 with competing models. An overview of the performance of the flagship Llama 3 model on key
benchmarks is presented in Table 2. Our experimental evaluation suggests that our flagship model performs
on par with leading language models such as GPT-4 (OpenAI, 2023a) across a variety of tasks, and is close to
matching the state-of-the-art. Our smaller models are best-in-class, outperforming alternative models with
similar numbers of parameters (Bai et al., 2023; Jiang et al., 2023). Llama 3 also delivers a much better
balance between helpfulness and harmlessness than its predecessor (Touvron et al., 2023b). We present a
detailed analysis of the safety of Llama 3 in Section 5.4.
We are publicly releasing all three Llama 3 models under an updated version of the Llama 3 Community License;
see https://llama.meta.com. This includes pre-trained and post-trained versions of our 405B parameter
language model and a new version of our Llama Guard model (Inan et al., 2023) for input and output safety.
We hope that the open release of a flagship model will spur a wave of innovation in the research community,
and accelerate a responsible path towards the development of artificial general intelligence (AGI).
As part of the Llama 3 development process we also develop multimodal extensions to the models, enabling
image recognition, video recognition, and speech understanding capabilities. These models are still under
active development and not yet ready for release. In addition to our language modeling results, the paper
presents results of our initial experiments with those multimodal models.
1The Llama 3 8B and 70B were pre-trained on multilingual data but were intended for use in English at the time.
2
�
B
8
3
a
m
a
L
l
Code
Math
General
Category
Benchmark
69.4
MMLU (5-shot)
MMLU (0-shot, CoT)
73.0
MMLU-Pro (5-shot, CoT)
48.3
IFEval
80.4
HumanEval (0-shot)
72.6
MBPP EvalPlus (0-shot)
72.8
GSM8K (8-shot, CoT)
84.5
MATH (0-shot, CoT)
51.9
83.4
ARC Challenge (0-shot)
32.8
GPQA (0-shot, CoT)
BFCL
76.1
Nexus
38.5
ZeroSCROLLS/QuALITY 81.0
65.1
InfiniteBench/En.MC
98.8
NIH/Multi-needle
Multilingual MGSM (0-shot, CoT)
68.9
Long context
Reasoning
Tool use
l
B
7
B
9
2
a
m
a
r
m
t
s
e
i
M
G
61.1
72.3
72.3 60.5
36.9
–
57.6
40.2
49.5
53.2
13.0
74.2
28.8
60.4
24.7
73.6
54.3
71.7
76.7
44.3
87.6
30.0
–
–
53.2
29.9
–
–
–
–
–
–
B
2
2
x
8
l
B
0
7
3
a
m
a
L
l
i
a
r
t
x
M
76.9
83.6
86.0 79.9
56.3
66.4
72.7
87.5
75.6
80.5
86.0 78.6
88.2
95.1
68.0 54.1
88.7
94.8
33.3
46.7
84.8
56.7
90.5
78.2
97.5
86.9
48.5
71.1
–
–
–
–
B
0
4
3
4
n
o
r
t
o
m
e
N
82.6
78.7
62.7
85.1
73.2
72.8
92.3♦
41.1
94.6
86.5
–
–
–
–
–
–
.
l
t
e
n
n
o
S
5
3
e
d
u
a
C
89.9
88.3
77.0
88.0
92.0
90.5
96.4♦
71.1
96.7
59.4
90.2
45.7
90.5
–
90.8
91.6
)
5
2
1
0
(
o
4
4
-
-
T
T
P
P
G
G
89.1
85.1
85.4
88.7
74.0
64.8
85.6
84.3
90.2
86.6
87.8
83.6
96.1
94.2
64.5
76.6
96.7
96.4
53.6
41.4
80.5
88.3
56.1
50.3
90.5
95.2
72.1
82.5
100.0 100.0
85.9
90.5
B
5
0
4
3
a
m
a
L
l
87.3
88.6
73.3
88.6
89.0
88.6
96.8
73.8
96.9
51.1
88.5
58.7
95.2
83.4
98.1
91.6
.
o
b
r
u
T
5
3
T
P
G
70.7
69.8
49.2
69.9
68.0
82.0
81.6
43.1
83.7
30.8
85.9
37.2
–
–
–
51.4
Table 2 Performance of finetuned Llama 3 models on key benchmark evaluations. The table compares the performance of
the 8B, 70B, and 405B versions of Llama 3 with that of competing models. We boldface the best-performing model in
each of three model-size equivalence classes. Results obtained using 5-shot prompting (no CoT). Results obtained
without CoT. ♦Results obtained using zero-shot prompting.
2 General Overview
The model architecture of Llama 3 is illustrated in Figure 1. The development of our Llama 3 language
models comprises two main stages:
• Language model pre-training. We start by converting a large, multilingual text corpus to discrete tokens
and pre-training a large language model (LLM) on the resulting data to perform next-token prediction.
In the language model pre-training stage, the model learns the structure of language and obtains large
amounts of knowledge about the world from the text it is “reading”. To do this effectively, pre-training
is performed at massive scale: we pre-train a model with 405B parameters on 15.6T tokens using a
context window of 8K tokens. This standard pre-training stage is followed by a continued pre-training
stage that increases the supported context window to 128K tokens. See Section 3 for details.
• Language model post-training. The pre-trained language model has a rich understanding of language
but it does not yet follow instructions or behave in the way we would expect an assistant to. We
align the model with human feedback in several rounds, each of which involves supervised finetuning
(SFT) on instruction tuning data and Direct Preference Optimization (DPO; Rafailov et al., 2024).
At this post-training2 stage, we also integrate new capabilities, such as tool-use, and observe strong
improvements in other areas, such as coding and reasoning. See Section 4 for details. Finally, safety
mitigations are also incorporated into the model at the post-training stage, the details of which are
described in Section 5.4.
The resulting models have a rich set of capabilities. They can answer questions in at least eight languages,
write high-quality code, solve complex reasoning problems, and use tools out-of-the-box or in a zero-shot way.
We also perform experiments in which we add image, video, and speech capabilities to Llama 3 using a
compositional approach. The approach we study comprises the three additional stages illustrated in Figure 28:
• Multi-modal encoder pre-training. We train separate encoders for images and speech. We train our
image encoder on large amounts of image-text pairs. This teaches the model the relation between visual
content and the description of that content in natural language. Our speech encoder is trained using a
2In this paper, we use the term “post-training” to refer to any model training that happens outside of pre-training.
3
�
Figure 1 Illustration of the overall architecture and training of Llama 3. Llama 3 is a Transformer language model trained to
predict the next token of a textual sequence. See text for details.
self-supervised approach that masks out parts of the speech inputs and tries to reconstruct the masked
out parts via a discrete-token representation. As a result, the model learns the structure of speech
signals. See Section 7 for details on the image encoder and Section 8 for details on the speech encoder.
• Vision adapter training. We train an adapter that integrates the pre-trained image encoder into the
pre-trained language model. The adapter consists of a series of cross-attention layers that feed image-
encoder representations into the language model. The adapter is trained on text-image pairs. This
aligns the image representations with the language representations. During adapter training, we also
update the parameters of the image encoder but we intentionally do not update the language-model
parameters. We also train a video adapter on top of the image adapter on paired video-text data. This
enables the model to aggregate information across frames. See Section 7 for details.
• Speech adapter training. Finally, we integrate the speech encoder into the model via an adapter that
converts speech encodings into token representations that can be fed directly into the finetuned language
model. The parameters of the adapter and encoder are jointly updated in a supervised finetuning stage
to enable high-quality speech understanding. We do not change the language model during speech
adapter training. We also integrate a text-to-speech system. See Section 8 for details.
Our multimodal experiments lead to models that can recognize the content of images and videos, and support
interaction via a speech interface. These models are still under development and not yet ready for release.
3 Pre-Training
Language model pre-training involves: (1) the curation and filtering of a large-scale training corpus, (2) the
development of a model architecture and corresponding scaling laws for determining model size, (3) the
development of techniques for efficient pre-training at large scale, and (4) the development of a pre-training
recipe. We present each of these components separately below.
3.1 Pre-Training Data
We create our dataset for language model pre-training from a variety of data sources containing knowledge
until the end of 2023. We apply several de-duplication methods and data cleaning mechanisms on each data
source to obtain high-quality tokens. We remove domains that contain large amounts of personally identifiable
information (PII), and domains with known adult content.
3.1.1 Web Data Curation
Much of the data we utilize is obtained from the web and we describe our cleaning process below.
PII and safety filtering. Among other mitigations, we implement filters designed to remove data from websites
are likely to contain unsafe content or high volumes of PII, domains that have been ranked as harmful
according to a variety of Meta safety standards, and domains that are known to contain adult content.
4
�
Text extraction and cleaning. We process the raw HTML content for non-truncated web documents to extract
high-quality diverse text. To do so, we build a custom parser that extracts the HTML content and optimizes
for precision in boilerplate removal and content recall. We evaluate our parser’s quality in human evaluations,
comparing it with popular third-party HTML parsers that optimize for article-like content, and found it
to perform favorably. We carefully process HTML pages with mathematics and code content to preserve
the structure of that content. We maintain the image alt attribute text since mathematical content is often
represented as pre-rendered images where the math is also provided in the alt attribute. We experimentally
evaluate different cleaning configurations. We find markdown is harmful to the performance of a model that
is primarily trained on web data compared to plain text, so we remove all markdown markers.
De-duplication. We apply several rounds of de-duplication at the URL, document, and line level:
• URL-level de-duplication. We perform URL-level de-duplication across the entire dataset. We keep the
most recent version for pages corresponding to each URL.
• Document-level de-duplication. We perform global MinHash (Broder, 1997) de-duplication across the
entire dataset to remove near duplicate documents.
• Line-level de-duplication. We perform aggressive line-level de-duplication similar to ccNet (Wenzek
et al., 2019). We remove lines that appeared more than 6 times in each bucket of 30M documents.
Although our manual qualitative analysis showed that the line-level de-duplication removes not only
leftover boilerplate from various websites such as navigation menus, cookie warnings, but also frequent
high-quality text, our empirical evaluations showed strong improvements.
Heuristic filtering. We develop heuristics to remove additional low-quality documents, outliers, and documents
with excessive repetitions. Some examples of heuristics include:
• We use duplicated n-gram coverage ratio (Rae et al., 2021) to remove lines that consist of repeated
content such as logging or error messages. Those lines could be very long and unique, hence cannot be
filtered by line-dedup.
• We use “dirty word” counting (Raffel et al., 2020) to filter out adult websites that are not covered by
domain block lists.
• We use a token-distribution Kullback-Leibler divergence to filter out documents containing excessive
numbers of outlier tokens compared to the training corpus distribution.
Model-based quality filtering. Further, we experiment with applying various model-based quality classifiers
to sub-select high-quality tokens. These include using fast classifiers such as fasttext (Joulin et al., 2017)
trained to recognize if a given text would be referenced by Wikipedia (Touvron et al., 2023a), as well as more
compute-intensive Roberta-based classifiers (Liu et al., 2019a) trained on Llama 2 predictions. To train a
quality classifier based on Llama 2, we create a training set of cleaned web documents, describe the quality
requirements, and instruct Llama 2’s chat model to determine if the documents meets these requirements. We
use DistilRoberta (Sanh et al., 2019) to generate quality scores for each document for efficiency reasons. We
experimentally evaluate the efficacy of various quality filtering configurations.
Code and reasoning data. Similar to DeepSeek-AI et al. (2024), we build domain-specific pipelines that extract
code and math-relevant web pages. Specifically, both the code and reasoning classifiers are DistilledRoberta
models trained on web data annotated by Llama 2. Unlike the general quality classifier mentioned above, we
conduct prompt tuning to target web pages containing math deduction, reasoning in STEM areas and code
interleaved with natural language. Since the token distribution of code and math is substantially different
than that of natural language, these pipelines implement domain-specific HTML extraction, customized text
features and heuristics for filtering.
Multilingual data. Similar to our processing pipelines for English described above, we implement filters to
remove data from websites that are likely to contain PII or unsafe content. Our multilingual text processing
pipeline has several unique features:
• We use a fasttext-based language identification model to categorize documents into 176 languages.
• We perform document-level and line-level de-duplication within data for each language.
5
�
• We apply language-specific heuristics and model-based filters to remove low-quality documents.
In addition, we perform quality ranking of multilingual documents using a multilingual Llama 2-based classifier
to ensure that high-quality content is prioritized. We determine the amount of multilingual tokens used in
pre-training experimentally, balancing model performance on English and multilingual benchmarks.
3.1.2 Determining the Data Mix
To obtain a high-quality language model, it is essential to carefully determine the proportion of different data
sources in the pre-training data mix. Our main tools in determining this data mix are knowledge classification
and scaling law experiments.
Knowledge classification. We develop a classifier to categorize the types of information contained in our web
data to more effectively determine a data mix. We use this classifier to downsample data categories that are
over-represented on the web, for example, arts and entertainment.
Scaling laws for data mix. To determine the best data mix, we perform scaling law experiments in which we
train several small models on a data mix and use that to predict the performance of a large model on that mix
(see Section 3.2.1). We repeat this process multiple times for different data mixes to select a new data mix
candidate. Subsequently, we train a larger model on this candidate data mix and evaluate the performance of
that model on several key benchmarks.
Data mix summary. Our final data mix contains roughly 50% of tokens corresponding to general knowledge,
25% of mathematical and reasoning tokens, 17% code tokens, and 8% multilingual tokens.
3.1.3 Annealing Data
Empirically, we find that annealing (see Section 3.4.3) on small amounts of high-quality code and mathematical
data can boost the performance of pre-trained models on key benchmarks. Akin to Li et al. (2024b), we
perform annealing with a data mix that upsamples high-quality data in select domains. We do not include
any training sets from commonly used benchmarks in our annealing data. This enables us to assess the true
few-shot learning capabilities and out-of-domain generalization of Llama 3.
Following OpenAI (2023a), we evaluate the efficacy of annealing on the GSM8k (Cobbe et al., 2021) and
MATH (Hendrycks et al., 2021b) training sets in annealing. We find that annealing improved the performance
of a pre-trained Llama 3 8B model on the GSM8k and MATH validation sets by 24.0% and 6.4%, respectively.
However, the improvements on the 405B model are negligible, suggesting that our flagship model has strong
in-context learning and reasoning capabilities and does not require specific in-domain training samples to
obtain strong performance.
Using annealing to assess data quality. Similar to Blakeney et al. (2024), we find that annealing enables us to
judge the value of small domain-specific datasets. We measure the value of such datasets by annealing the
learning rate of a 50% trained Llama 3 8B model linearly to 0 on 40B tokens. In those experiments, we assign
30% weight to the new dataset and the remaining 70% weight to the default data mix. Using annealing to
evaluate new data sources is more efficient than performing scaling law experiments for every small dataset.
3.2 Model Architecture
Llama 3 uses a standard, dense Transformer architecture (Vaswani et al., 2017). It does not deviate significantly
from Llama and Llama 2 (Touvron et al., 2023a,b) in terms of model architecture; our performance gains are
primarily driven by improvements in data quality and diversity as well as by increased training scale.
We do make a few smaller modifications compared to Llama 3:
• We use grouped query attention (GQA; Ainslie et al. (2023)) with 8 key-value heads to improve inference
speed and to reduce the size of key-value caches during decoding.
• We use an attention mask that prevents self-attention between different documents within the same
sequence. We find that this change had limited impact during in standard pre-training, but find it to be
important in continued pre-training on very long sequences.
6
�
8B
32
4,096
6,144
32
8
3 × 10−4
Layers
Model Dimension
FFN Dimension
Attention Heads
Key/Value Heads
Peak Learning Rate
Activation Function
Vocabulary Size
Positional Embeddings
70B
80
8192
12,288
64
8
405B
126
16,384
20,480
128
8
8 × 10−5
1.5 × 10−4
SwiGLU
128,000
RoPE (θ = 500, 000)
Table 3 Overview of the key hyperparameters of Llama 3. We display settings for 8B, 70B, and 405B language models.
• We use a vocabulary with 128K tokens. Our token vocabulary combines 100K tokens from the tiktoken3
tokenizer with 28K additional tokens to better support non-English languages. Compared to the Llama
2 tokenizer, our new tokenizer improves compression rates on a sample of English data from 3.17 to
3.94 characters per token. This enables the model to “read” more text for the same amount of training
compute. We also found that adding 28K tokens from select non-English languages improved both
compression ratios and downstream performance, with no impact on English tokenization.
• We increase the RoPE base frequency hyperparameter to 500,000. This enables us to better support
longer contexts; Xiong et al. (2023) showed this value to be effective for context lengths up to 32,768.
Llama 3 405B uses an architecture with 126 layers, a token representation dimension of 16,384, and 128
attention heads; see Table 3 for details. This leads to a model size that is approximately compute-optimal
according to scaling laws on our data for our training budget of 3.8 × 1025 FLOPs.
3.2.1 Scaling Laws
We develop scaling laws (Hoffmann et al., 2022; Kaplan et al., 2020) to determine the optimal model size for
our flagship model given our pre-training compute budget. In addition to determining the optimal model size,
a major challenge is to forecast the flagship model’s performance on downstream benchmark tasks, due to a
couple of issues: (1) Existing scaling laws typically predict only next-token prediction loss rather than specific
benchmark performance. (2) Scaling laws can be noisy and unreliable because they are developed based on
pre-training runs conducted with small compute budgets (Wei et al., 2022b).
To address these challenges, we implement a two-stage methodology to develop scaling laws that accurately
predict downstream benchmark performance:
1. We first establish a correlation between the compute-optimal model’s negative log-likelihood on down-
stream tasks and the training FLOPs.
2. Next, we correlate the negative log-likelihood on downstream tasks with task accuracy, utilizing both the
scaling law models and older models trained with higher compute FLOPs. In this step, we specifically
leverage the Llama 2 family of models.
This approach enables us to predict downstream task performance given a specific number of training FLOPs
for compute-optimal models. We use a similar method to select our pre-training data mix (see Section 3.4).
Scaling law experiments. Concretely, we construct our scaling laws by pre-training models using compute
budgets between 6 × 1018 FLOPs and 1022 FLOPs. At each compute budget, we pre-train models ranging
in size between 40M and 16B parameters, using a subset of model sizes at each compute budget. In these
training runs, we use a cosine learning rate schedule with a linear warmup for 2,000 training steps. The peak
learning rate is set between 2 × 10−4 and 4 × 10−4 depending on the size of the model. We set the cosine
decay to 0.1 of the peak value. The weight decay at each step is set to 0.1 times the learning rate at that step.
We use a fixed batch size for each compute scale, ranging between 250K and 4M.
3https://github.com/openai/tiktoken/tree/main
7
�
Figure 2 Scaling law IsoFLOPs curves between 6 × 1018
and 1022 FLOPs. The loss is the negative log-
likelihood on a held-out validation set. We approx-
imate measurements at each compute scale using a
second degree polynomial.
Figure 3 Number of training tokens in identified compute-
optimal models as a function of pre-training compute
budget. We include the fitted scaling-law prediction
as well. The compute-optimal models correspond to
the parabola minimums in Figure 2.
These experiments give rise to the IsoFLOPs curves in Figure 2. The loss in these curves is measured on
a separate validation set. We fit the measured loss values using a second-degree polynomial and identify
the minimums of each parabola. We refer to minimum of a parabola as the compute-optimal model at the
corresponding pre-training compute budget.
We use the compute-optimal models we identified this way to predict the optimal number of training tokens
for a specific compute budget. To do so, we assume a power-law relation between compute budget, C, and
the optimal number of training tokens, N (C):
N (C) = AC α.
We fit A and α using the data from Figure 2. We find that (α, A) = (0.53, 0.29); the corresponding fit is
shown in Figure 3. Extrapolation of the resulting scaling law to 3.8 × 1025 FLOPs suggests training a 402B
parameter model on 16.55T tokens.
An important observation is that IsoFLOPs curves become flatter around the minimum as the compute
budget increases. This implies that performance of the flagship model is relatively robust to small changes in
the trade-off between model size and training tokens. Based on this observation, we ultimately decided to
train a flagship model with 405B parameters.
Predicting performance on downstream tasks. We use the resulting compute-optimal models to forecast
the performance of the flagship Llama 3 model on benchmark data sets. First, we linearly correlate the
(normalized) negative log-likelihood of correct answer in the benchmark and the training FLOPs. In this
analysis, we use only the scaling law models trained up to 1022 FLOPs on the data mix described above. Next,
we establish a sigmoidal relation between the log-likelihood and accuracy using both the scaling law models
and Llama 2 models, which were trained using the Llama 2 data mix and tokenizer. We show the results of
this experiment on the ARC Challenge benchmark in Figure 4). We find this two-step scaling law prediction,
which extrapolates over four orders of magnitude, to be quite accurate: it only slightly underestimates the
final performance of the flagship Llama 3 model.
3.3 Infrastructure, Scaling, and Efficiency
We describe our hardware and infrastructure that powered Llama 3 405B pre-training at scale and discuss
several optimizations that leads to improvements in training efficiency.
3.3.1 Training Infrastructure
The Llama 1 and 2 models were trained on Meta’s AI Research SuperCluster (Lee and Sengupta, 2022). As
we scaled further, the training for Llama 3 was migrated to Meta’s production clusters (Lee et al., 2024).This
8
101010111012Training Tokens0.700.750.800.850.900.95Validation LossCompute6e181e193e196e191e203e206e201e213e211e221019102010211022Compute (FLOPs)10101011Training TokensFitted Line, = 0.537, A = 0.299�









 ACS0709(传感器资料).PDF
ACS0709(传感器资料).PDF 495个C语言常见问题集.pdf
495个C语言常见问题集.pdf 仿真-LM386模拟电路(嵌入式音频资料).rar
仿真-LM386模拟电路(嵌入式音频资料).rar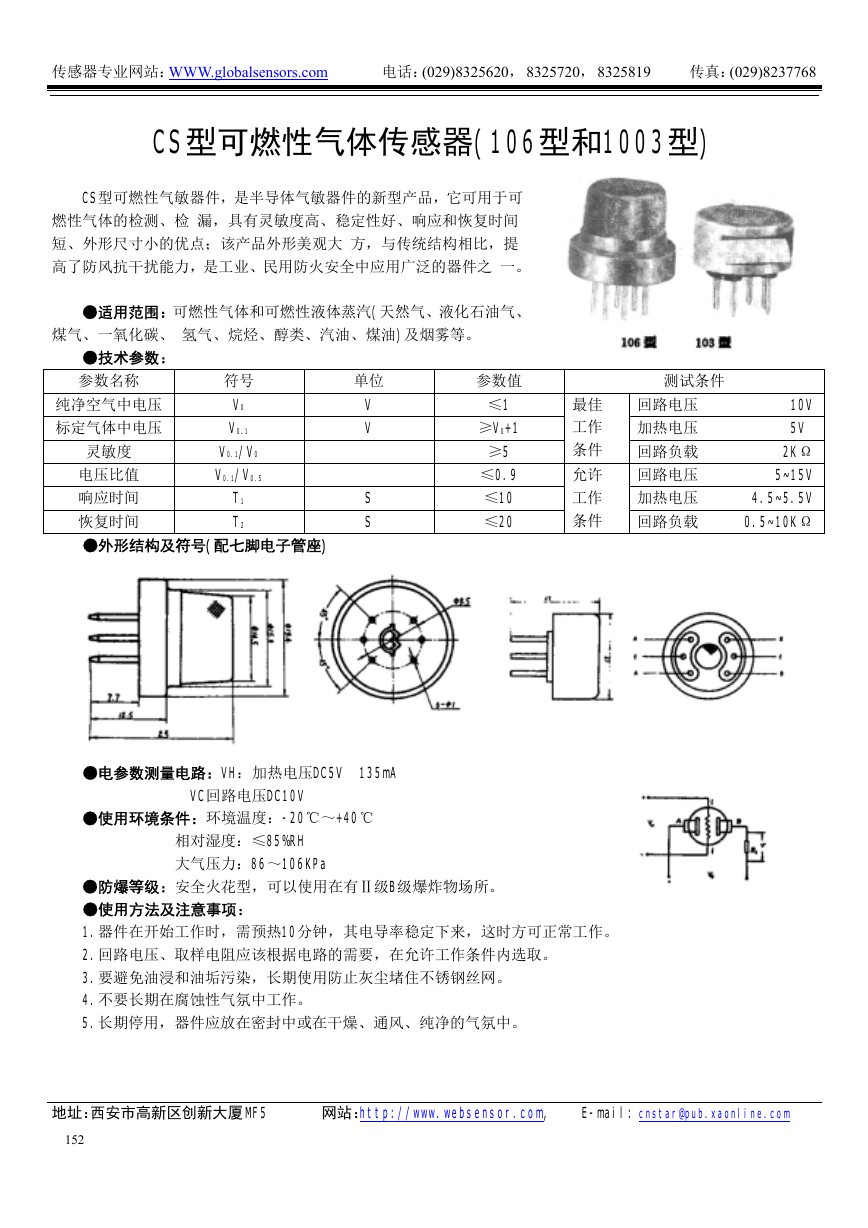 CS型可燃性气体传感器(106型和1003型)(传感器资料).pdf
CS型可燃性气体传感器(106型和1003型)(传感器资料).pdf 一种基于PWM的电压输出DAC电路设计.pdf
一种基于PWM的电压输出DAC电路设计.pdf cd4011b(智能车电机驱动).pdf
cd4011b(智能车电机驱动).pdf 电路设计规范_中兴.pdf
电路设计规范_中兴.pdf HA50-P(传感器资料).pdf
HA50-P(传感器资料).pdf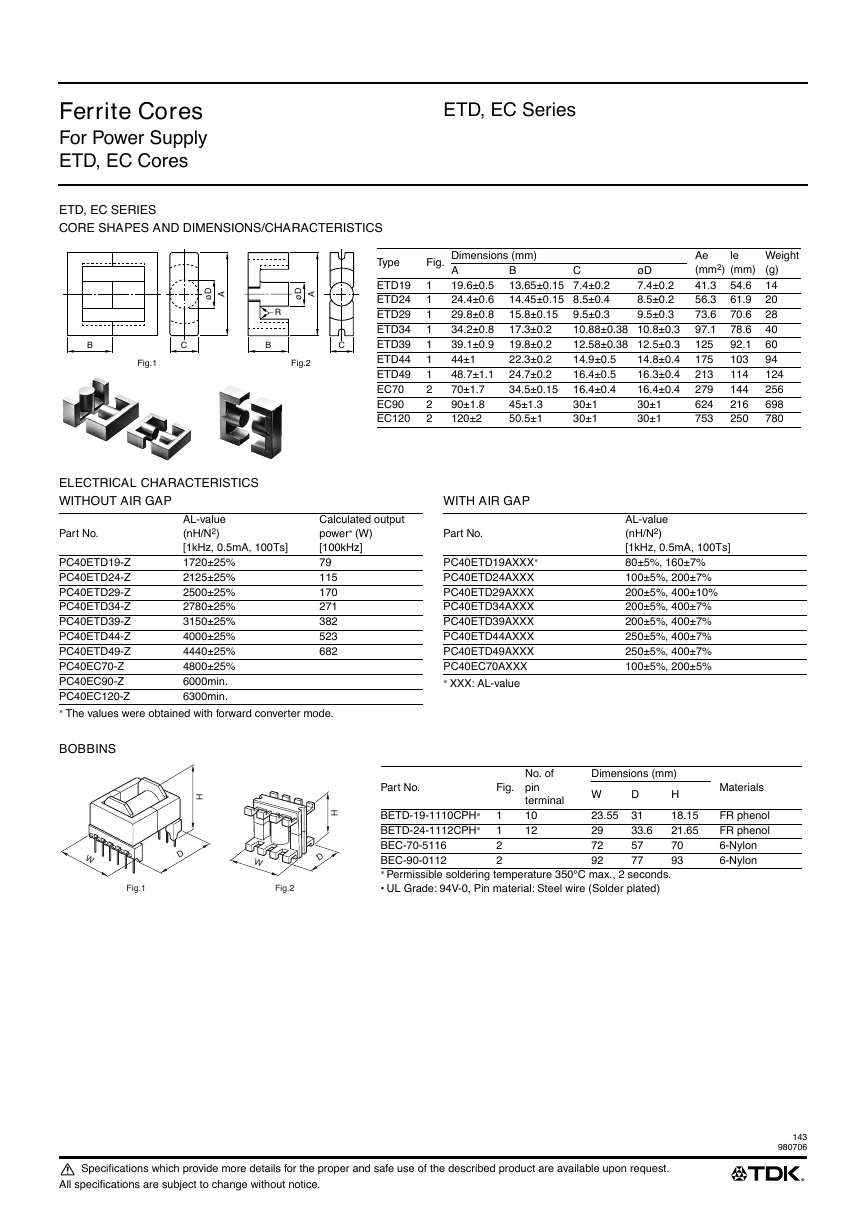 ETD-core(TDK磁芯资料).pdf
ETD-core(TDK磁芯资料).pdf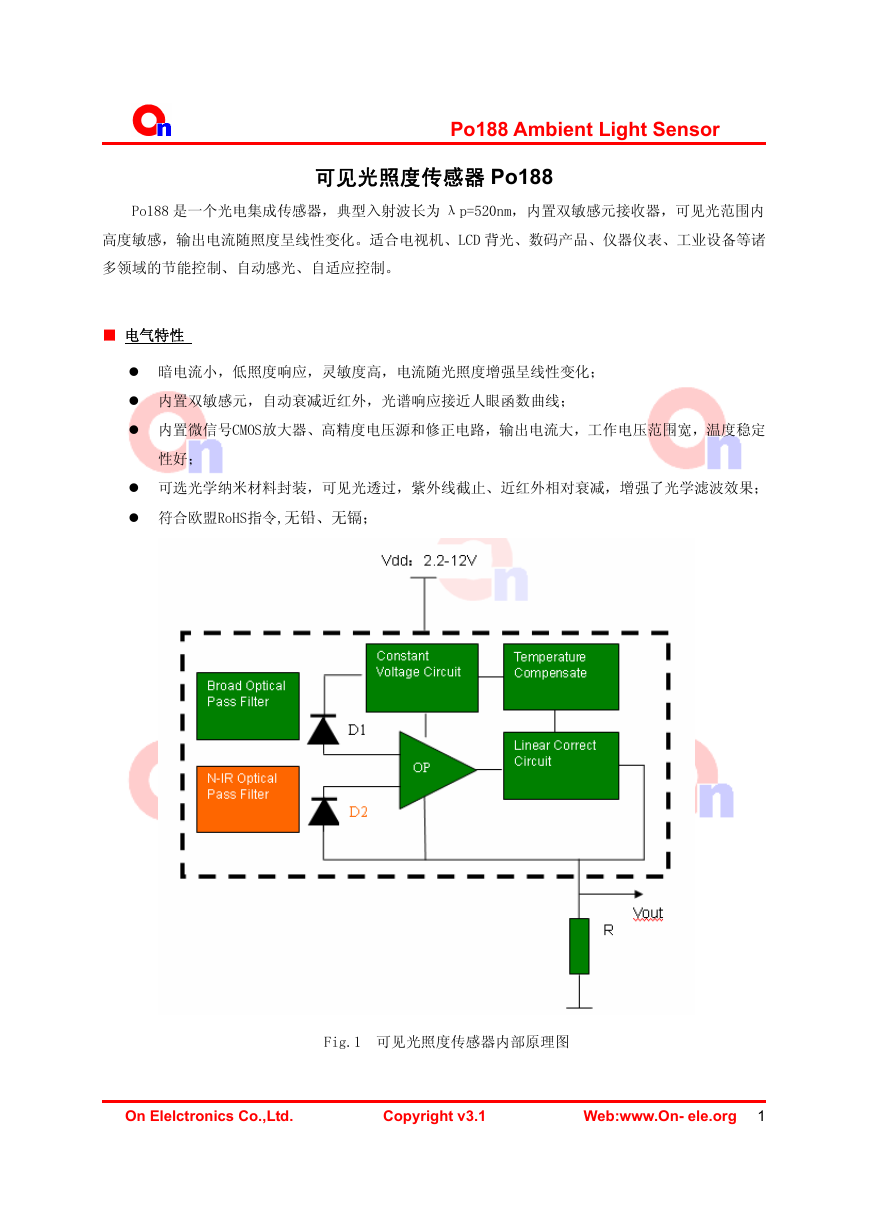 Po188-c[1](传感器资料).pdf
Po188-c[1](传感器资料).pdf






