第 9 章 图象的压缩编码,JPEG 压缩编
码标准
在介绍图象的压缩编码之前,先考虑一个问题:为什么要压缩?其实这个问题不用我回
答,你也能想得到。因为图象信息的数据量实在是太惊人了。举一个例子就明白:一张
A4(210mm×297mm) 幅面的照片,若用中等分辨率(300dpi)的扫描仪按真彩色扫描,其数据
量为多少?让我们来计算一下:共有(300×210/25.4) ×(300×297/25.4)个象素,每个象素占 3
个字节,其数据量为 26M 字节,其数据量之大可见一斑了。
如今在 Internet 上,传统基于字符界面的应用逐渐被能够浏览图象信息的 WWW(World Wide
Web)方式所取代。WWW 尽管漂亮,但是也带来了一个问题:图象信息的数据量太大了,
本来就已经非常紧张的网络带宽变得更加不堪重负,使得 World Wide Web 变成了 World
Wide Wait。
总之,大数据量的图象信息会给存储器的存储容量,通信干线信道的带宽,以及计算机的处
理速度增加极大的压力。单纯靠增加存储器容量,提高信道带宽以及计算机的处理速度等方
法来解决这个问题是不现实的,这时就要考虑压缩。
压缩的理论基础是信息论。从信息论的角度来看,压缩就是去掉信息中的冗余,即保留不确
定的信息,去掉确定的信息(可推知的),也就是用一种更接近信息本质的描述来代替原有冗
余的描述。这个本质的东西就是信息量(即不确定因素)。
压缩可分为两大类:第一类压缩过程是可逆的,也就是说,从压缩后的图象能够完全恢复出
原来的图象,信息没有任何丢失,称为无损压缩;第二类压缩过程是不可逆的,无法完全恢
复出原图象,信息有一定的丢失,称为有损压缩。选择哪一类压缩,要折衷考虑,尽管我们
希望能够无损压缩,但是通常有损压缩的压缩比(即原图象占的字节数与压缩后图象占的字
节数之比,压缩比越大,说明压缩效率越高)比无损压缩的高。
图象压缩一般通过改变图象的表示方式来达到,因此压缩和编码是分不开的。图象压缩的主
要应用是图象信息的传输和存储,可广泛地应用于广播电视、电视会议、计算机通讯、传真、
多媒体系统、医学图象、卫星图象等领域。
压缩编码的方法有很多,主要分成以下四大类:(1)象素编码;(2)预测编码;(3)变换编码;
(4)其它方法。
所谓象素编码是指,编码时对每个象素单独处理,不考虑象素之间的相关性。在象素编码中
常用的几种方法有:(1)脉冲编码调制(Pulse Code Modulation,简称 PCM);(2)熵编码(Entropy
Coding);(3)行程编码(Run Length Coding);(4)位平面编码(Bit Plane Coding)。其中我们要介
绍的是熵编码中的哈夫曼(Huffman)编码和行程编码(以读取.PCX 文件为例)。
�
所谓预测编码是指,去除相邻象素之间的相关性和冗余性,只对新的信息进行编码。举个简
单的例子,因为象素的灰度是连续的,所以在一片区域中,相邻象素之间灰度值的差别可能
很小。如果我们只记录第一个象素的灰度,其它象素的灰度都用它与前一个象素灰度之差来
表示,就能起到压缩的目的。如 248,2,1,0,1,3,实际上这 6 个象素的灰度是 248,250,
251,251,252,255。表示 250 需要 8 个比特,而表示 2 只需要两个比特,这样就实现了压
缩。
常用的预测编码有Δ调制(Delta Modulation,简称 DM);微分预测编码(Differential Pulse Code
Modulation,DPCM),具体的细节在此就不详述了。
所谓变换编码是指,将给定的图象变换到另一个数据域(如频域)上,使得大量的信息能用较
少的数据来表示,从而达到压缩的目的。变换编码有很多,如(1)离散傅立叶变换(Discrete
Fourier Transform,简称 DFT);(2)离散余弦变换(Discrete Cosine Transform,简称 DCT);(3)
离散哈达玛变换(Discrete Hadamard Transform,简称 DHT)。
其它的编码方法也有很多,如混合编码(Hybird Coding)、矢量量化(Vector Quantize,VQ) 、
LZW 算法。在这里,我们只介绍 LZW 算法的大体思想。
值得注意的是,近些年来出现了很多新的压缩编码方法,如使用人工神经元网络(Artificial
Neural Network,简称 ANN)的压缩编码算法、分形(Fractl)、小波(Wavelet) 、基于对象(Object
Based)的压缩编码算法、基于模型(Model –Based)的压缩编码算法(应用在 MPEG4 及未来的
视频压缩编码标准中)。这些都超出了本书的范围。
本章的最后,我们将以 JPEG 压缩编码标准为例,看看上面的几种编码方法在实际的压缩编
码中是怎样应用的。
9.1 哈夫曼编码
哈夫曼(Huffman)编码是一种常用的压缩编码方法,是 Huffman 于 1952 年为压缩文本文件建
立的。它的基本原理是频繁使用的数据用较短的代码代替,较少使用的数据用较长的代码代
替,每个数据的代码各不相同。这些代码都是二进制码,且码的长度是可变的。举个例子:
假设一个文件中出现了 8 种符号 S0,S1,S2,S3,S4,S5,S6,S7,那么每种符号要编码,至少需要
3 比 特 。 假 设 编 码 成 000,001,010,011,100,101,110,111( 称 做 码 字 ) 。 那 么 符 号 序 列
S0S1S7S0S1S6S2S2S3S4S5S0S0S1
成
000001111000001110010010011100101000000001,共用了 42 比特。我们发现 S0,S1,S2
这三个符号出现的频率比较大,其它符号出现的频率比较小,如果我们采用一种编码方案使
得 S0,S1,S2 的码字短,其它符号的码字长,这样就能够减少占用的比特数。例如,我们
采用这样的编码方案:S0 到 S7 的码字分别 01,11,101,0000,0001,0010,0011,100,那么上述符
号序列变成 011110001110011101101000000010010010111,共用了 39 比特,尽管有些码字
编
码
后
变
�
如 S3,S4,S5,S6 变长了(由 3 位变成 4 位),但使用频繁的几个码字如 S0,S1 变短了,所
以实现了压缩。
上述的编码是如何得到的呢?随意乱写是不行的。编码必须保证不能出现一个码字和另一个
的前几位相同的情况,比如说,如果 S0 的码字为 01,S2 的码字为 011,那么当序列中出现
011 时,你不知道是 S0 的码字后面跟了个 1,还是完整的一个 S2 的码字。我们给出的编码
能够保证这一点。
下面给出具体的 Huffman 编码算法。
(1) 首先统计出每个符号出现的频率,上例 S0 到 S7 的出现频率分别为 4/14,3/14,2/14,
1/14,1/14,1/14,1/14,1/14。
(2) 从左到右把上述频率按从小到大的顺序排列。
(3) 每一次选出最小的两个值,作为二叉树的两个叶子节点,将和作为它们的根节点,
这两个叶子节点不再参与比较,新的根节点参与比较。
(4) 重复(3),直到最后得到和为 1 的根节点。
(5) 将形成的二叉树的左节点标 0,右节点标 1。把从最上面的根节点到最下面的叶子
节点途中遇到的 0,1 序列串起来,就得到了各个符号的编码。
上面的例子用 Huffman 编码的过程如图 9.1 所示,其中圆圈中的数字是新节点产生的顺序。
可见,我们上面给出的编码就是这么得到的。
�
图 9.1 Huffman 编码的示意图
产生 Huffman 编码需要对原始数据扫描两遍。第一遍扫描要精确地统计出原始数据中,每
个值出现的频率,第二遍是建立 Huffman 树并进行编码。由于需要建立二叉树并遍历二叉
树生成编码,因此数据压缩和还原速度都较慢,但简单有效,因而得到广泛的应用。
源程序就不给出了,有兴趣的读者可以自己实现。
9.2 行程编码
行程编码(Run Length Coding)的原理也很简单:将一行中颜色值相同的相邻象素用一个计数
值和该颜色值来代替。例如 aaabccccccddeee 可以表示为 3a1b6c2d3e。如果一幅图象是由很
多块颜色相同的大面积区域组成,那么采用行程编码的压缩效率是惊人的。然而,该算法也
导致了一个致命弱点,如果图象中每两个相邻点的颜色都不同,用这种算法不但不能压缩,
反而数据量增加一倍。所以现在单纯采用行程编码的压缩算法用得并不多,PCX 文件算是
其中的一种。
PCX 文件最早是 PC Paintbrush 软件所采用的一种文件格式,由于压缩比不高,现在用的并
不是很多了。它也是由头信息、调色板、实际的图象数据三个部分组成。其中头信息的结构
为:
typedef struct{
char manufacturer;
char version;
char encoding;
char bits_per_pixel;
WORD xmin,ymin;
WORD xmax,ymax;
WORD hres;
WORD vres;
char palette[48];
char reserved;
�
char colour_planes;
WORD bytes_per_line;
WORD palette_type;
char filler[58];
} PCXHEAD;
其中值得注意的是以下几个数据:manufacturer 为 PCX 文件的标识,必须为 0x0a;xmin 为
最小的 x 坐标,xmax 最大的 x 坐标,所以图象的宽度为 xmax-xmin+1,同样图象的高度为
ymax-yin+1;bytes_per_line 为每个编码行所占的字节数,下面将详细介绍。
PCX 的调色板在文件的最后。以 256 色 PCX 文件为例,倒数第 769 个字节为颜色数的标识,
256 时该字节必须为 12,剩下的 768(256×3)为调色板的 RGB 值。
为了叙述方便,我们针对 256 色 PCX 文件,介绍一下它的解码过程。编码是解码的逆过程,
有兴趣的读者可以试着自己来完成。
解码是以行为单位的,该行所占的字节数由 bytes_per_line 给定。为此,我们开一个大小为
bytes_per_line 的解码缓冲区。一开始,将缓冲区的所有内容清零。从文件中读出一个字节 C,
若 C>0xc0,说明是行程(Run Length)信息,即 C 的低 6 位表示后面连续的字节个数(所以最
多 63 个连续颜色相同的象素,若还有颜色相同的象素,将在下一个行程处理),文件的下一
个字节就是实际的图象数据(即该颜色在调色板中的索引值)。若 C<0xc0,则表示 C 是实际
的图象数据。如此反复,直到这 bytes_per_line 个字节处理完,这一行的解码完成。PCX 就
是有若干个这样的解码行组成。
下面是实现 256 色 PCX 文件解码的源程序,其中第二个函数对一行进行解码,应该把阅读
的重点放在这个函数上。要注意的是,执行时文件 C:\\test.pcx 必须存在,而且是一个 256
色 PCX 文件。
unsigned int PcxBytesPerLine;
BOOL LoadPcxFile (HWND hWnd,char *PcxFileName)
{
FILE *PCXfp;
PCXHEAD header;
�
LOGPALETTE *pPal;
HPALETTE hPrevPalette;
HDC hDc;
HLOCAL hPal;
DWORD ImgSize;
DWORD OffBits,BufSize;
LPBITMAPINFOHEADER lpImgData;
DWORD i;
LONG x,y;
int PcxTag;
unsigned char LineBuffer[6400];
LPSTR lpPtr;
HFILE hfbmp;
if((PCXfp=fopen(PcxFileName,"rb"))==NULL){ //文件没有找到
MessageBox(hWnd,"File c:\\test.pcx not found!","Error Message",
MB_OK|MB_ICONEXCLAMATION);
return FALSE;
}
//读出头信息
fread((char*)&header,1,sizeof(PCXHEAD),PCXfp);
if(header.manufacturer!=0x0a){ //不是一个合法的 PCX 文件
MessageBox(hWnd,"Not a valid Pcx file!","Error Message",
�
MB_OK|MB_ICONEXCLAMATION);
fclose(PCXfp);
return FALSE;
}
//将文件指针指向调色板开始处
fseek(PCXfp,-769L,SEEK_END);
//获取颜色数信息
PcxTag=fgetc(PCXfp)&0xff;
if(PcxTag!=12){ //非 256 色,返回
MessageBox(hWnd,"Not a 256 colors Pcx file!","Error Message",
MB_OK|MB_ICONEXCLAMATION);
fclose(PCXfp);
return FALSE;
}
//创建新的 BITMAPFILEHEADER 和 BITMAPINFOHEADER
memset((char *)&bf,0,sizeof(BITMAPFILEHEADER));
memset((char *)&bi,0,sizeof(BITMAPINFOHEADER));
//填写 BITMAPINFOHEADER 头信息
bi.biSize=sizeof(BITMAPINFOHEADER);
//得到图象的宽和高
bi.biWidth=header.xmax-header.xmin+1;
bi.biHeight=header.ymax-header.ymin+1;
�
bi.biPlanes=1;
bi.biBitCount=8;
bi.biCompression=BI_RGB;
ImgWidth=bi.biWidth;
ImgHeight=bi.biHeight;
NumColors=256;
LineBytes=(DWORD)WIDTHBYTES(bi.biWidth*bi.biBitCount);
ImgSize=(DWORD)LineBytes*bi.biHeight;
//填写 BITMAPFILEHEADER 头信息
bf.bfType=0x4d42;
bf.bfSize=sizeof(BITMAPFILEHEADER)+sizeof(BITMAPINFOHEADER)+
NumColors*sizeof(RGBQUAD)+ImgSize;
bf.bfOffBits=(DWORD)(NumColors*sizeof(RGBQUAD)+
sizeof(BITMAPFILEHEADER)+sizeof(BITMAPINFOHEADER));
//为新图分配缓冲区
if((hImgData=GlobalAlloc(GHND,(DWORD)
(sizeof(BITMAPINFOHEADER)+
NumColors*sizeof(RGBQUAD)+ImgSize)))==NULL)
{
MessageBox(hWnd,"Error alloc memory!","ErrorMessage",
MB_OK|MB_ICONEXCLAMATION);
fclose(PCXfp);
�









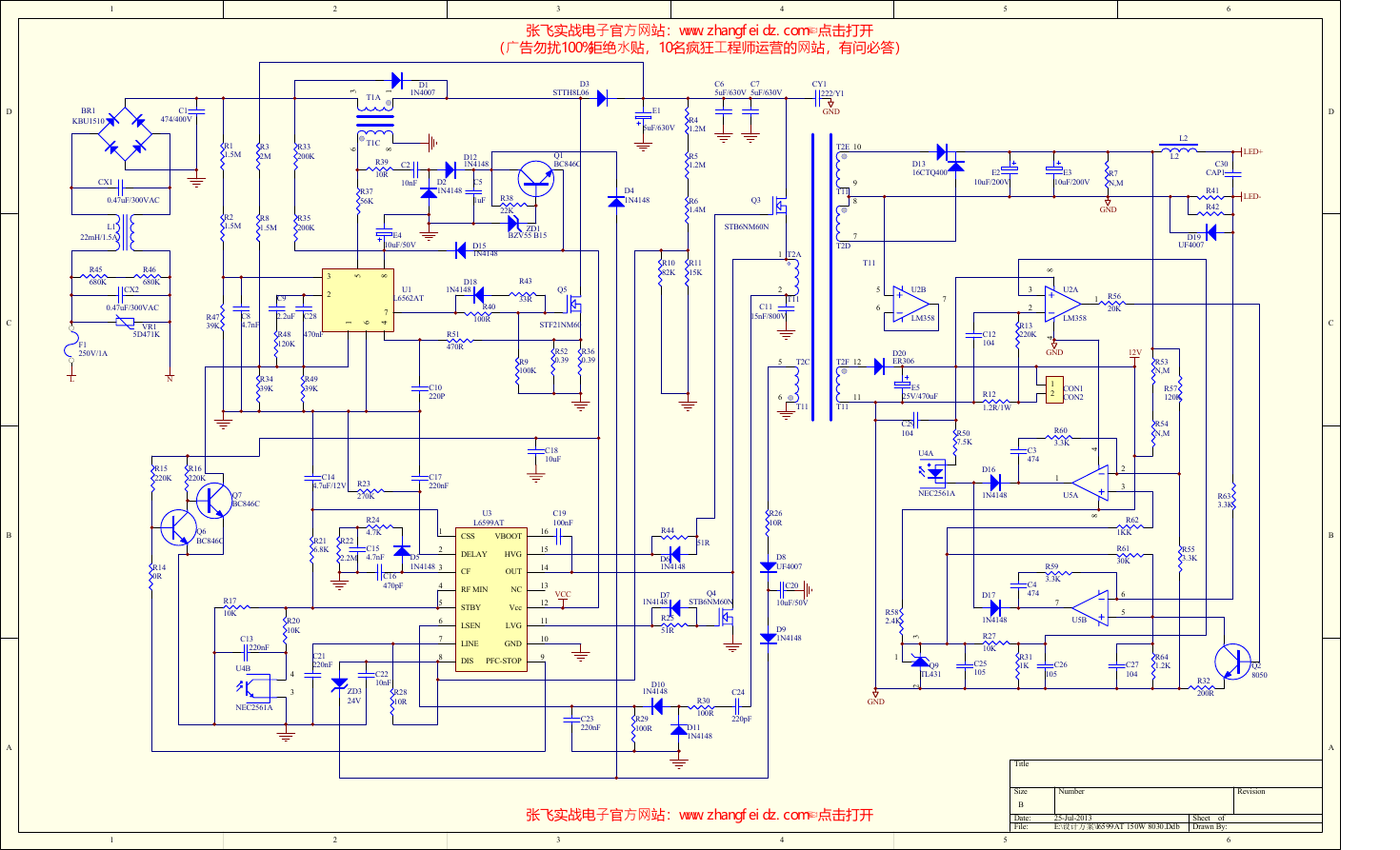
 2025年软考高级信息系统项目管理师金色考点
2025年软考高级信息系统项目管理师金色考点 软考高项三色笔记
软考高项三色笔记 镇安县双鑫矿业月河年处理15万吨尾渣综合加工利用项目水土保持报告表
镇安县双鑫矿业月河年处理15万吨尾渣综合加工利用项目水土保持报告表  红杉资本:生成式AI最新市场格局.pdf
红杉资本:生成式AI最新市场格局.pdf wireshark 使用教程.pdf
wireshark 使用教程.pdf 【2021年-贝佐斯致股东的信】.pdf
【2021年-贝佐斯致股东的信】.pdf 巴菲特致股东的公开信 - 2022.pdf
巴菲特致股东的公开信 - 2022.pdf MySQL 8.1 参考手册.pdf
MySQL 8.1 参考手册.pdf 世界银行报告下载:激进政策缩紧浪潮不足遏制通胀 全球经济衰退迫在眉睫(Is a Global Recession Imminent?).pdf
世界银行报告下载:激进政策缩紧浪潮不足遏制通胀 全球经济衰退迫在眉睫(Is a Global Recession Imminent?).pdf 红杉资本报告:适应与忍耐(Adapting to Endure).pdf
红杉资本报告:适应与忍耐(Adapting to Endure).pdf 高保真音响系统设计制作-毕业论文.doc
高保真音响系统设计制作-毕业论文.doc 一种自适应互补滤波姿态估计算法.pdf
一种自适应互补滤波姿态估计算法.pdf