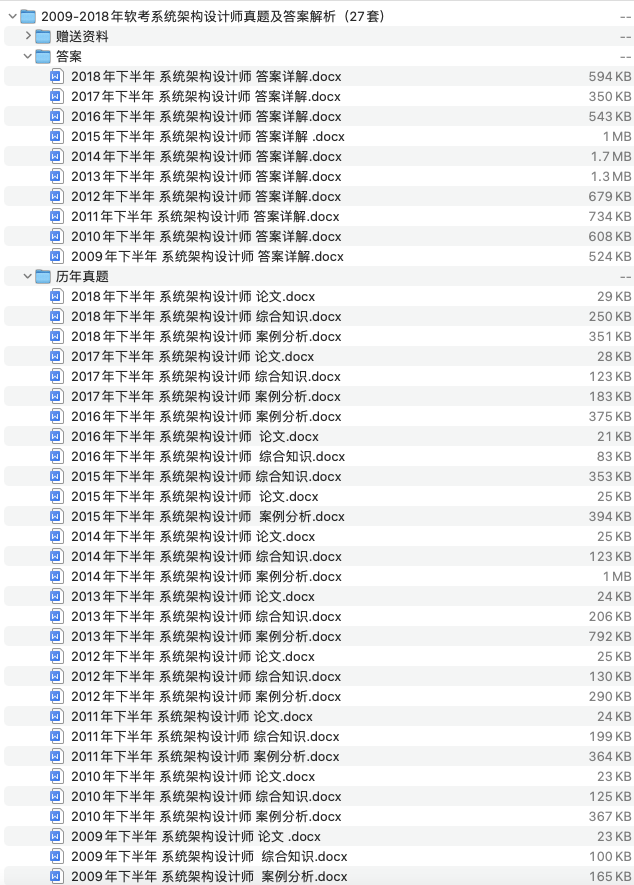
分布式缓存对应需要的实现组件有:
一个缓存监控、迁移、管理中心。
一个自定义的客户端组件,上图中的 SmartClient。
一个无状态的代理服务。
N 台服务器。
179.Redis 是什么?都有哪些使用场景?180.Redis 有哪些功能?
180.实力讲解 redis:缓存穿透,缓存雪崩,缓存击穿
缓存穿透,雪崩,击穿
https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc
181.Redis 和 MemeCache 有什么区别?
1)、存储方式 Memecache 把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大
小。 Redis 有部份存在硬盘上,这样能保证数据的持久性。 2)、数据支持类型 Memcache
对数据类型支持相对简单。 Redis 有复杂的数据类型。 3)、使用底层模型不同 它们之间底
层实现方式 以及与客户端之间通信的应用协议不一样。 Redis 直接自己构建了 VM 机制 ,
因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求。
182.Redis 为什么是单线程的?
因为 redis 利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销。
183.什么是缓存穿透?怎么解决?
缓存穿透以及解决
https://blog.csdn.net/qq_16681169/article/details/75138876
184.Redis 支持的数据类型有哪些?
1.redis 的 5 种数据类型: string 字符串(可以为整形、浮点型和字符串,统称为元素) list
列表(实现队列,元素不唯一,先入先出原则) set 集合(各不相同的元素)
hash hash 散列值(hash 的 key 必须是唯一的) sort set 有序集合
185.Redis 支持的 Java 客户端都有哪些?
Redis Desktop Manager 、Redis Client、Redis Studio、jedis
186.Jedis 和 Redisson 有哪些区别?
Jedis 是 Redis 的 java 实现客户端,其 API 提供了比较全面的 Redis 命令的支持;Redisson 实
现了分布式和可扩展的 Java 数据结构,和 Jedis 相比,功能较为简单,不支持字符串操作,
不支持排序、事务‘管道、分区等 Redis 特性。Redisson 的宗旨是促进使用者对 Redis 的关
注分离,从而让使用者能够将精力更集中地放在处理业务逻辑上。
187.怎么保证缓存和数据库数据的一致性?
由于数据库层面的读写并发,引发的数据库与缓存数据不一致的问题(本质是后发生的读请
求先返回了),可能通过两个小的改动解决:(1)修改服务 Service 连接池,id 取模选取服务
连接,能够保证同一个数据的读写都落在同一个后端服务上(2)修改数据库 DB 连接池,id
取模选取 DB 连接,能够保证同一个数据的读写在数据库层面是串行的
�
188.Redis 持久化有几种方式?
Redis 是一种高级 key-value 数据库。它跟 memcached 类似,不过数据可以持久化,而且支
持的数据类型很丰富。有字符串,链表,集 合和有序集合。支持在服务器端计算集合的并,
交和补集(difference)等,还支持多种排序功能。所以 Redis 也可以被看成是一个数据结构服
务 器。Redis 的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这
称为“半持久化模式”);也可以把每一次数据变化都写入到一个 append only file(aof)里面(这
称为“全持久化模式”)。
189.Redis 怎么实现分布式锁?
Redis 的实现主要基于 setnx 和给予一个超时时间(防止释放锁失败)。 多个尝试获取锁的
客户端使用同一个 key 做为目标数据的唯一键,value 为锁的期望超时时间点; 首先进行一
次 setnx 命令,尝试获取锁,如果获取成功,则设置锁的最终超时时间(以防在当前进程获
取锁后奔溃导致锁无法释放)这里利用 Redis set key 时的一个 NX 参数可以保证在这个
key 不存在的情况下写入成功。并且再加上 EX 参数可以让该 key 在超时之后自动删除。
一定不要把两个命令(NX EX)分开执行,如果在 NX 之后程序出现问题就有可能产生死锁。
非阻塞锁、阻塞锁、解锁、为了更好的健壮性,将该操作封装为一个 lua 脚本,这样即可保
证其原子性 redis 分布式的实现原理:
1、通过 setNX 操作,如果存在 key,不操作;不存在,才会 set 值,保证锁的互斥性 2、value
设置锁的到期时间,当锁超时时,进行 getAndSet 操作,先 get 旧值,再 set 新值,避免发
生死锁。这里也可以通过设置 key 的有效期来避免死锁,但是 setNx 和 exprise(设置有效期)
操作非原子性,可能发生锁没有设置有效时间的问题,从而发生死锁。实现:spring boot 通
过 jdeis 连接 redsi 集群。
加锁过程:
1、获得当前系统时间,计算锁的到期时间
2、setNx 操作,加锁
3、如果,加锁成功,设置锁的到期时间,返回 true;取锁失败,取出当前锁的 value(到期
时间)
4、如果 value 不为空而且小于当前系统时间,进行 getAndSet 操作,重新设置 value,并取
出旧 value;否则,等待间隔时间后,重复步骤 2;
5、如果步骤 3 和 4 取出的 value 一样,加锁成功,设置锁的到期时间,返回 true;否则,
别人加锁成功,恢复锁的 value,等待间隔时间后,重复步骤 2。
190.Redis 分布式锁有什么缺陷?
在工作和网络上看到过各个版本的 Redis 分布式锁实现,每种实现都有一些不严谨的地方,
甚至有可能是错误的实现,包括在代码中,如果不能正确的使用分布式锁,可能造成严重的
生产环境故障。
redis 分布式锁的缺陷
https://blog.csdn.net/matt8/article/details/64442064
191.Redis 如何做内存优化?
1,使用对象共享池优化小整数对象。
�
2,数据优先使用整数,比字符串更节省空间。3,操作优化。尽量避免字符串的追加操作,
因为字符串存在预分配机制。追加操作后字符串对象会分配一倍的容量作为于预留空间。4,
编码优化。list,hash,set,zset 尽可能使用 ziplist 编码。好处是内存下降,坏处是操作变慢。
一般大小不超过 1000。
192.Redis 淘汰策略有哪些?
redis 提供 6 种数据淘汰策略:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据
淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-enviction(驱逐):禁止驱逐数据
193.Redis 常见的性能问题有哪些?
该如何解决?1.master 写内存快照,seve 命令调度 rdbsave 函数,会阻塞主线程的工程,当
快照比较大的时候对性能的影响是非常大的,会间断性暂停服务 。所以 master 最好不要写
内存快照。2.master AOF 持久化,如果不重写 AOF 文件,这个持久化方式对性能的影响是最
小的,但是 AOF 文件会不断增大,AOF 文件过大会影响 master 重启时的恢复速度。master
最好不要做任何持久化工作,包括内存快照和 AOF 日志文件,特别是不要启用内存快照做
持久化,如果数据比较关键,某个 slave 开启 AOF 备份数据,策略每秒为同步一次。3.master
调用 BGREWRITEAOF 重写 AOF 文件,AOF 在重写的时候会占大量的 CPU 和内存资源,导致
服务 load 过高,出现短暂的服务暂停现象。4.redis 主从复制的性能问题,为了主从复制的
速度和连接的稳定性,slave 和 master 最好在同一个局域网内。
�